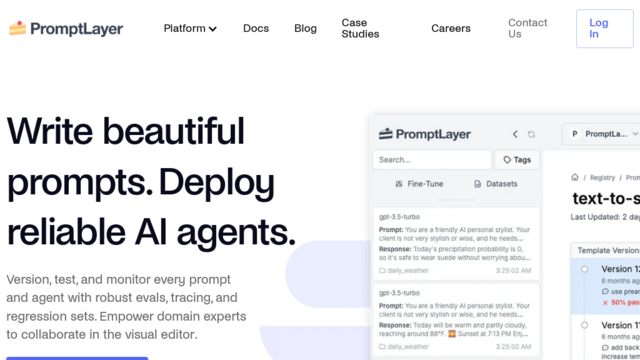
PromptLayer is a specialized developer tool and middleware platform designed to manage the lifecycle of LLM prompts. It acts as a bridge between your application code and AI providers (like OpenAI or Anthropic), capturing every request and response to create a searchable system of record. By decoupling prompts from the core codebase into a ‘Prompt Registry,’ it allows teams to version, test, and deploy instructions in real-time without requiring a full engineering release. This ‘Prompt CMS’ approach empowers non-technical domain experts to iterate on AI behavior safely while providing developers with deep observability into costs and performance.
Use Cases
Collaborative Prompt Engineering
Enable product managers, lawyers, or medical experts to edit and test prompt templates directly in a visual dashboard without touching the underlying Python or JavaScript code.
Regression Testing & Backtesting
Evaluate how a prompt change or a new model version (e.g., upgrading from GPT-4 to GPT-5) impacts your historical data before deploying to production.
Production Observability & Debugging
Trace exactly which prompt version was used for a specific customer complaint, and review the full request/response metadata to diagnose hallucinations or errors.
Cost & Latency Optimization
Monitor real-time spending and response times across different models and tags to identify expensive or slow prompts that need refactoring.
A/B Testing AI Personalities
Safely split traffic between two prompt variants (e.g., ‘concise’ vs. ‘friendly’) and use real-world performance data to determine the optimal release.
Features & Benefits
Visual Prompt Registry (CMS)
A centralized, Git-inspired repository for prompt templates featuring version control, visual diffs, and side-by-side variant comparisons.
Middleware SDK Wrapping
Simple drop-in replacements for standard LLM libraries (OpenAI, Anthropic, etc.) that automatically log all metadata and requests with zero impact on app stability.
Automated Evaluation Pipelines
Schedule regression tests and batch runs against custom datasets, utilizing ‘LLM-as-a-judge’ or human review loops to score outputs.
Advanced Analytics Dashboard
Detailed tracking of token usage, costs, latency, and custom metadata (like user_id or environment) for every single API call.
Multi-Model Playgrounds
A browser-based workspace to experiment with prompts across 250+ providers simultaneously to find the best-performing model for a specific task.
Empowers Cross-Functional Teams
Removes the engineering bottleneck by allowing domain experts to own the ‘vibe’ and accuracy of the AI, while developers handle the infrastructure.
SOC 2 & HIPAA Compliance
Enterprise-grade security and data privacy certifications make it suitable for regulated industries like healthcare and finance.
Git-Style Reliability
Provides a clear ‘commit history’ for prompts, allowing teams to roll back instantly if a new prompt version causes production issues.
Cons
Steep Learning Curve for Evaluations
Setting up rigorous automated evaluation metrics and backtests can require significant AI engineering expertise.
High Cost for Scale
While the free tier is generous, the ‘Team’ and ‘Enterprise’ plans represent a significant jump in budget for smaller startups.